Topic Modeling
Abstract
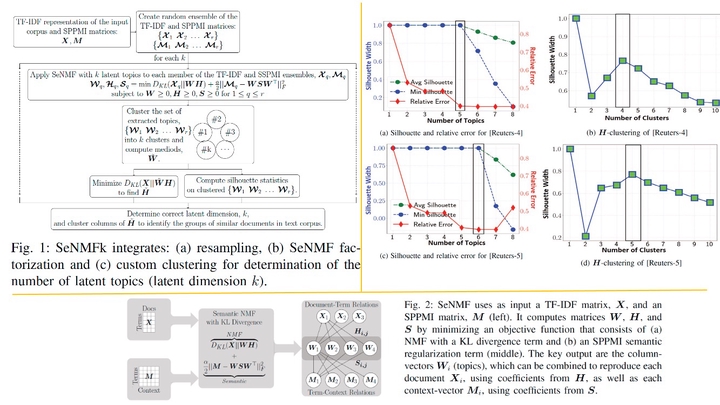
Non-negative Matrix Factorization (NMF) models the topics of a text corpus by decomposing the matrix of term frequency-inverse document frequency (TF-IDF) representation, X, into two low-rank non-negative matrices: W , representing the topics and H, mapping the documents onto space of topics. One challenge, common to all topic models, is the determination of the number of latent topics (aka model determination). Determining the correct number of topics is important: underestimating the number of topics results in a poor topic separation, under-fitting, while overestimating leads to noisy topics, over-fitting. Here, we introduce SeNMFk, a semantic-assisted NMF-based topic modeling method, which incorporates semantic correlations in NMF by using a word-context matrix, and employs a method for determination of the number of latent topics. SeNMFk first creates a random ensemble of matrices based on the initial TF-IDF matrix and a word-context matrix, and then applies a coupled factorization to acquire sets of stable coherent topics that are robust to noise. The latent dimension is determined based on the stability of these topics. We show that SeNMFk accurately determines the number of high-quality topics in benchmark text corpora, which leads to an accurate document clustering.